Vous créez des images à l’aide de l’IA. Vous en avez même un sacré stock sur votre PC et sur les plateformes que vous utilisez. Mais, comme vous ne maîtrisez pas l’intégralité du processus, la gestion des prompts est fastidieuse, voire, tout simple, vous ne sauvegardez pas vos prompts. Ce qui vous rend très dépendant des plateformes.
Voici un petit billet, plutôt théorique, vous présentant la solution à ce problème.
Métadonnées
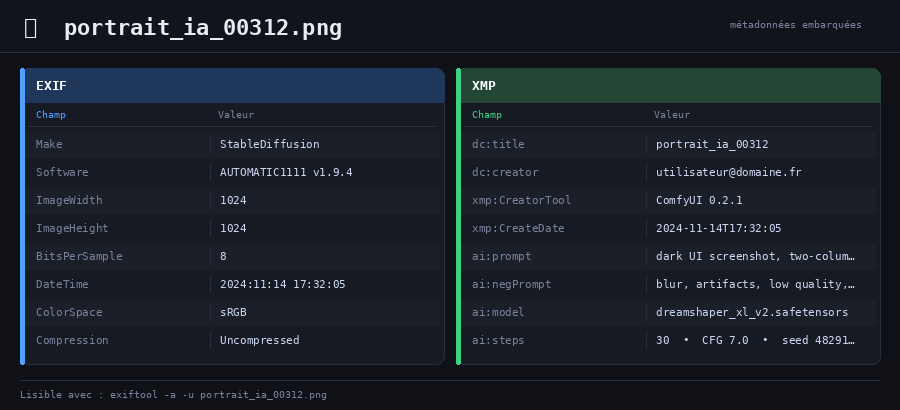
Exemple de métadonnées EXIF et XMP dans une image générée par IA – le prompt et les paramètres de génération sont stockés directement dans le fichier.
Une image numérique c’est beaucoup plus que de simples pixels. Un fichier contient des informations qui vont au-delà de la simple image. Ces informations peuvent décrire le fichier (taille, date), la façon dont il a été créé (marque de l’appareil photographie, objectif utilisé), ou tout autre détail technique (espace colorimétrique, coordonnées GPS). Ces informations sont appelées des métadonnées (metadata en anglais).
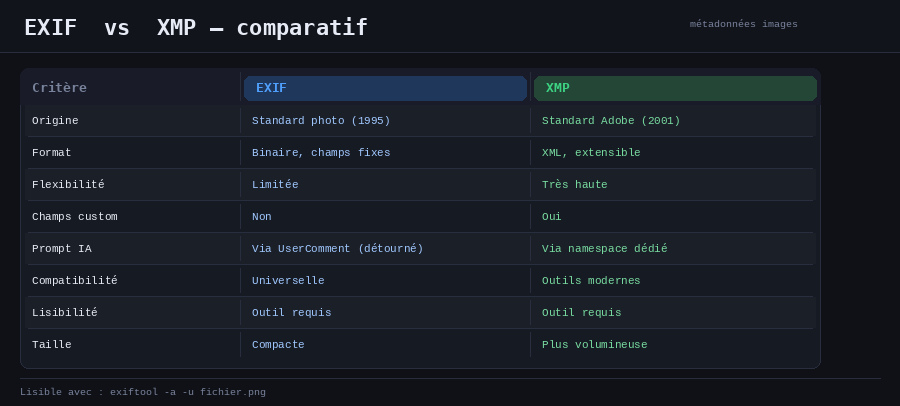
Deux formats dominent : EXIF, ancien et rigide, pensé pour les appareils photo ; et XMP, plus souple, extensible à volonté. C’est ce dernier qui intéresse surtout les outils d’IA.
Comparatif simplifié entre les données EXIF et les données XMP
De nombreux logiciels permettent de créer, modifier ou supprimer ces métadonnées. Pour la gestion des prompts, et autres informations de générations, c’est donc une solution très simple et très efficace.
Le cas de l’IA
Lorsqu’une image est générée par une IA il est possible d’écrire les informations de génération (prompt, LLM, etc.). Certains logiciels, comme Stable Diffusion, le fond automatiquement. Mais avec la plupart, les images générées ne contiendront pas d’information utile.
L’utilisation de logiciel comme ExifTool devient donc obligatoire pour gérer les métadonnées. Ainsi vos images deviendront autodocumentées, et leur gestion en sera largement simplifiée.
Conclusion
La gestion des métadonnées n’est pas une lubie d’infographiste sur le retour, c’est le premier pas vers une démarche de professionnalisation de la création d’image.
Dans de prochains billets, nous verrons comment travailler ses données.
Lors d’un premier tutoriel nous avons vu comment créer une carte simple avec MapLibre. Maintenant nous allons voir comment la décorer et la rendre un peu interactive. Pour ce faire, nous allons gérer les contrôles.
MapLibre fournit des outils de contrôles par défaut qui sont :
La navigation, qui consiste en deux boutons (+ et -) pour gérer le niveau de zoom et une boussole pour orienter la carte vers le nord ;
Le plein écran, qui consiste en un bouton, qui, comme son nom l’indique, permet de passer la carte en mode plein écran ;
L’échelle, qui permet d’évaluer rapidement les distances ;
La géolocalisation, qui permet de récupérer les coordonnées GPS du client et d’adapter la carte à celles-ci.
Tous ces contrôles sont implémentés en utilisant la méthode map.addControl(contrôle, position);
Il existe quatre positions :
'top-left'
'top-right'
'bottom-left'
'bottom-right'
Par défaut, les contrôles sont affichés en haut à droite (top-right). Lorsque plusieurs contrôles sont placés au même endroit, MapLibre va les empiler les uns au-dessus des autres. L’ordre d’ajout dans le code JavaScript devient donc très important, celui-ci étant suivi par MapLibre.
Navigation
// Zoom + boussole (en haut à droite)
map.addControl(
new maplibregl.NavigationControl(),
'top-right'
);
Ce code permet afficher les boutons pour contrôler le zoom et la boussole. La boussole permet de réorienter la carte vers le nord après que l’utilisateur a effectué une rotation.
Si votre carte est exclusivement en 2D, le code suivant permet de désactiver la rotation.
//Zoom sans boussole et rotation désactivée
const nav = new maplibregl.NavigationControl({
showCompass: false
});
map.addControl(nav, 'top-right');
Plein écran
// Plein écran (en haut à droite, sous la navigation)
map.addControl(
new maplibregl.FullscreenControl(),
'top-right'
);
Ce bouton permet de basculer en mode plein écran. C’est particulièrement utile pour les cartes intégrées dans une page Web proposant d’autres contenus.
Il n’y a pas d’option particulière à connaître pour un usage standard. MapLibre gère automatiquement l’entrée et la sortie du mode plein écran via l’API Fullscreen du navigateur.
Échelle
// Échelle (en bas à gauche)
map.addControl(
new maplibregl.ScaleControl({
maxWidth: 120,
unit: 'metric'
}),
'bottom-left'
);
Le `ScaleControl` affiche une règle graphique en bas de carte, indiquant la distance réelle correspondant à une longueur à l’écran. Elle se met à jour automatiquement lors du zoom.
Trois unités sont disponibles :
« metric », qui utilisera le mètre ou le kilomètre. Cette unité est utile pour la majorité des cartes.
« imperial », qui utilisera la verge (yard) ou le mille terrestre internationale (mile). Cette unité est utile pour les cartes destinées à un public anglo-saxon.
« nautical », qui utilisera le mille marin. Cette unité est utile pour les cartes marines.
Par convention, l’échelle se place en bas de la carte, le côté gauche étant le plus fréquemment utilisé.
Géolocalisation
// Géolocalisation (en haut à droite)
map.addControl(
new maplibregl.GeolocateControl({
positionOptions: { enableHighAccuracy: true },
trackUserLocation: true,
showAccuracyCircle: true
}),
'top-right'
);
Voici ce que font les principales options :
trackUserLocation — lorsque la valeur « true » est choisie, la carte suit la position de l’utilisateur en continu, comme un mode navigation. Lorsque « false » est choisie, la carte se centre une seule fois sur sa position.
showAccuracyCircle — cette option permet d’afficher un cercle semi-transparent autour du point GPS pour donner une idée de la précision de la localisation. C’est très utile pour signaler à l’utilisateur que sa position est approximative.
positionOptions.enableHighAccuracy — cette option indique au navigateur d’utiliser la source de localisation la plus précise disponible (le GPS plutôt que le WiFi ou le réseau mobile). En contrepartie, la position peut être légèrement plus longue à obtenir.
Il est important de retenir que l’API du navigateur Web exige que la page soit servie en HTTPS. Dans le cas contraire, l’API ne fonctionnera tout simplement pas. Le bouton s’affichera mais sera inactif. De toute manière, il est préférable d’utiliser HTTPS plutôt que HTTP.
Voilà, vous disposez maintenant du code pour gérer les contrôles fournis par MapLibre. Des contrôles personnalisés peuvent être créés, ce sera l’objet d’un autre tutoriel.
Le monde du WebMapping évolue, et, clairement, il n’y a pas que Leaflet dans la vie. Aujourd’hui, on va donc parler de tuiles vectorielles, de MapLibre et de MapTiler. En avant pour un petit tuto !
Depuis quelques années, il est possible d’utiliser des tuiles vectorielles pour les fonds de carte. Ce type de tuile permet notamment aux développeurs de personnaliser le style des cartes. Il est aussi possible d’auto-héberger les fichiers de styles, généralement au format JSON.
Pour les débutants, le mieux est de commencer avec des fournisseurs en ligne, comme MapTiler.
L’objectif ici sera simplement d’afficher une carte, avec un fond de carte utilisant des tuiles vectorielles. La gestion des données viendra un peu plus tard.
MapLibre sert à afficher la carte. MapTiler fournit ici les ressources cartographiques.
var map = new maplibregl.Map({
container: 'map', // container id
style: 'https://api.maptiler.com/maps/streets-v4/style.json?key=####', //style MapTiler
center: [2.895556, 42.698611], // starting position [lng, lat]
zoom: 10 // starting zoom
});
Explication
Le code est assez trivial. Les habitués de Leaflet n’auront aucun mal à le comprendre.
D’abord, il fait créer une variable qui permettra d’instancier l’objet MapLibre. Le container correspond à la div qui accueille la carte. Son identifiant est utilisé ici. Le style permet de gérer le fond de carte. Ici j’utilise un fond fourni par MapTiler. Pour cela, il faut créer un compte sur le site de MapTiler et récupérer une clé API. La clé doit être passée à la fin de l’URL (les ####). Le center correspond aux coordonnées du centre de la carte. Il faudra évidemment les choisir en fonction de vos besoins. On verra dans d’autres tutoriels comment automatiser cette tâche. Le zoom définit, comme son nom l’indique, le niveau de zoom au chargement de la carte. Les valeurs vont de 0 (le monde entier) à 22 (quelques pâtés de maisons).
Vous avez à présent le code nécessaire pour une première carte toute simple. Il ne reste plus qu’à la décorer et à la rendre interactive. La suite dans un prochain tutoriel.
On continue avec la gestion des événements de MySQL. Ce coup-ci l’objectif est d’exécuter plusieurs requêtes dans un même événement.
Principe
Dans le cadre de la maintenance courante d’une base de données il est fréquent d’exécuter un ensemble de requêtes s’appliquant à plusieurs tables. Si les opérations sont automatisées via des événements le développeur/administrateur a deux solutions pour la mise en œuvre de ces taches : créer plusieurs événements, chacun n’exécutant qu’une seule requête ; créer un événement exécutant plusieurs requêtes.
Les deux méthodes ont leurs avantages et leurs inconvénients. Dans le cas d’un événement exécutant plusieurs requêtes l’avantage principal sera la création d’une routine claire, avec la maîtrise de l’ordre d’exécution des requêtes.
Code
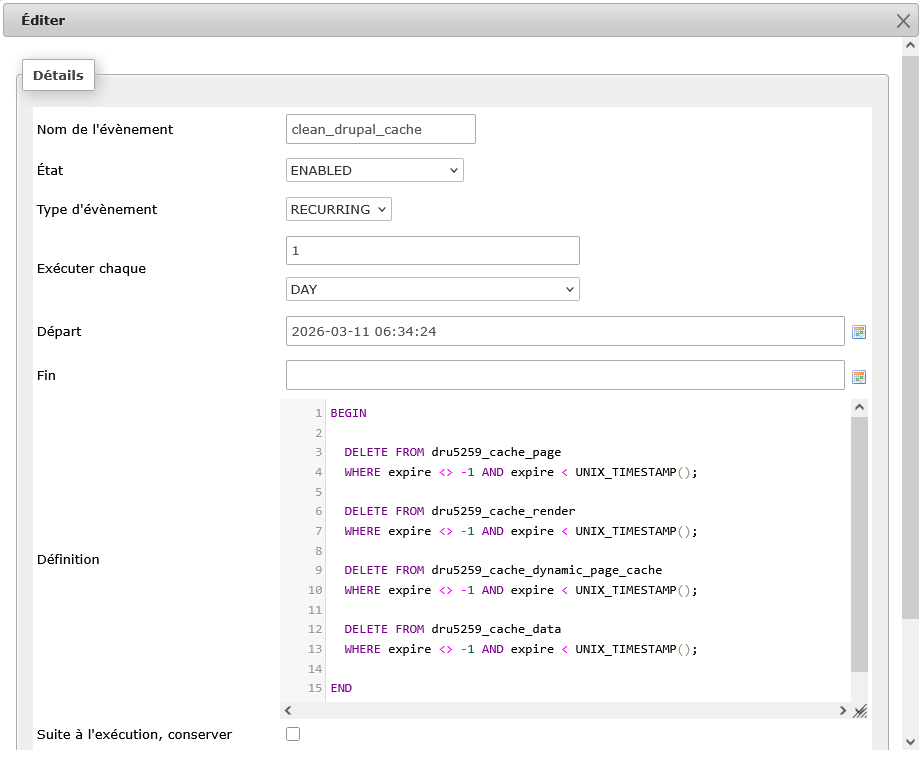
CREATE DEFINER=user EVENT `clean_drupal_cache` ON SCHEDULE EVERY 1 DAY STARTS '2026-03-11 06:34:24' ON COMPLETION NOT PRESERVE ENABLE COMMENT 'Vide les tables de cache' DO
BEGIN
DELETE FROM dru5259_cache_page WHERE expire <> -1 AND expire < UNIX_TIMESTAMP();
DELETE FROM dru5259_cache_render WHERE expire <> -1 AND expire < UNIX_TIMESTAMP();
DELETE FROM dru5259_cache_dynamic_page_cache WHERE expire <> -1 AND expire < UNIX_TIMESTAMP();
DELETE FROM dru5259_cache_data WHERE expire <> -1 AND expire < UNIX_TIMESTAMP();
END
Le code permet d’effacer tous les enregistrements dans les tables de cache vieux de plus d’un jour. N’oubliez pas d’adapter le « user » en fonction de votre configuration.
Démarche
Dans un premier il faut écrire et tester les requêtes une par une. De préférence avec une base de données de test. J’enfonce une porte ouverte, mais les fondamentaux doivent toujours être rappelés de temps en temps.
Une fois les requêtes fonctionnelles, il faudra les tester en bloc. Si rien ne casse, vous pouvez passez à l’écriture du code pour l’événement.
La première partie du code est triviale. Elle est identique à celle pour un événement n’exécutant qu’une seule requête.
La partie incluant les requêtes commence par BEGIN et finit par END. Entre ces deux mots clés il faudra écrire l’intégralité des requêtes SQL. Il est très important de ne pas oublier de finir les requêtes par un point virgule « ; ». Dans le cas contraire l’événement risque de ne pas s’exécuter du tout.
Concernant l’ordre d’exécution des requêtes, il faut préciser qu’elles seront exécutées séquentiellement. Elles s’exécuteront donc l’une après l’autre, dans l’ordre d’écriture, et seulement une fois que la requête précédente aura été exécutée. Il faut donc correctement définir cet ordre, sous peine de générer des erreurs, pouvant empêcher le bon fonctionnement de votre base de données.
Trucs et astuces
Vous utilisez phpMyAdmin pour créer vos événements ? Vous avez raison. Et vous êtes un battant !
Mais vous rencontrez des erreurs lorsque vous créer ce type d’événements.
Hormis les problèmes liés aux requêtes en elles-mêmes, phpMyAdmin peut afficher un message d’erreur s’il n’y a pas de ligne après BEGIN et avant END. Il faudra donc bien penser à sauter des lignes.
De la même manière n’hésitez pas à sauter des lignes entre chaque requête. Cela rendra votre code plus lisible et plus facile à maintenir.
Courant 2025 le site eixerit.info a connu de nombreux problèmes techniques, principalement dû à la base de données, tournant avec MySQL. Ces problèmes sont, en grande partie, réglés grâce à la création d’un événement en SQL, directement exécuté par le serveur de base de données. Voici un petit tutoriel sur le sujet.
Cas concret
En 2024 j’ai passé le site sous Drupal. L’installation a été réalisée directement depuis le back-office d’OVH. Rétrospectivement c’était sans doute une erreur, Drupal étant mal configuré au final. Le résultat a été que les tables de gestion des logs et la table watchdog se sont rapidement remplies, suite à des tentatives de création de faux comptes et d’utilisation d’URL erronées par des bots. En quelques jours la taille de la base de données dépassait donc les 512 Mo, soit la taille disponible dans le cadre de l’hébergement mutualisé que j’ai souscrit.
La solution simple consiste à effacer périodiquement ces tables.
Sauf que cette solution est contraignante. Il faut en effet se connecter fréquemment, effectuer les opérations, et vérifier que l’on n’a rien cassé.
L’idée pour évacuer cette contrainte est donc d’automatiser toutes ces opérations. Il existe plusieurs méthodes, mais la plus efficace et la plus simple est d’utiliser la fonction d’automatisation de MySQL, qui passe par la création d’un événement (event).
Principe
MySQL dispose de la possibilité de création d’événements temporel. En pratique une ou plusieurs requêtes SQL peuvent être exécutées automatiquement à des moments précis. Cela revient à utiliser un cron directement à l’intérieur du serveur.
Sous réserve de disposer des bons privilèges, n’importe quelle requête peut être exécutée. Cela permet d’automatiser la plupart des taches courantes d’administration.
Avant de créer un ou plusieurs événements, vous devrez vérifier que l’option est disponible pour votre hébergement. Pour vous assurer que le gestionnaire d’événements est activité il suffit de passer la commande SQL suivante :
SET GLOBAL event_scheduler = ON;
Code
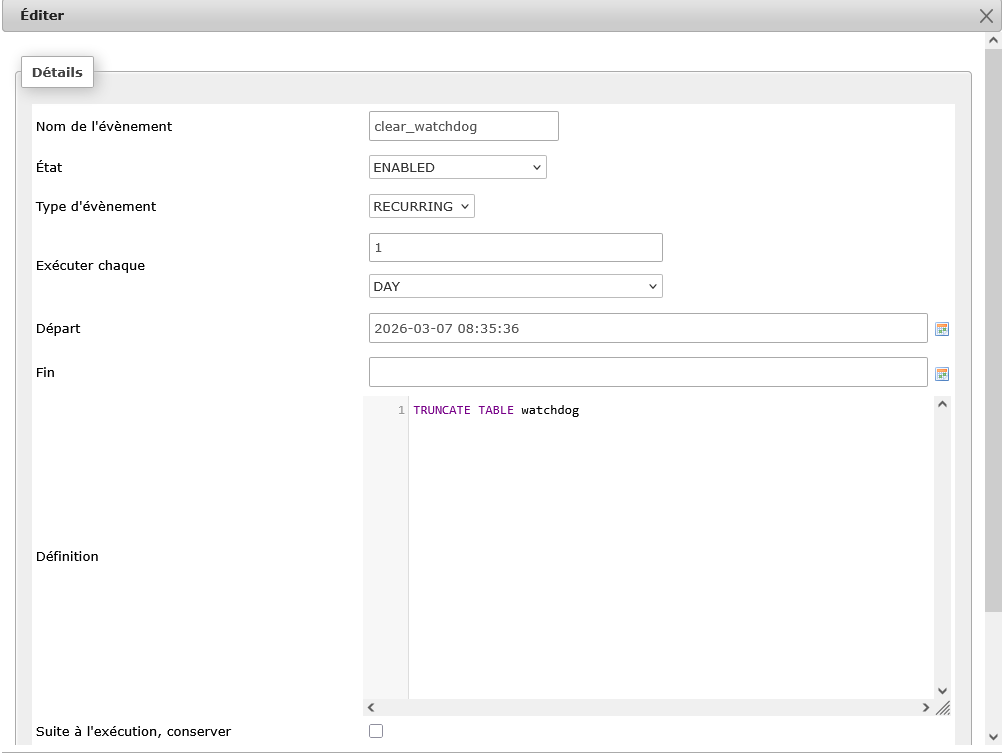
Le code pour la table watchdog :
CREATE DEFINER=user EVENT `clear_watchdog` ON SCHEDULE EVERY 1 DAY STARTS '2026-03-07 08:35:36' ON COMPLETION NOT PRESERVE ENABLE COMMENT 'Vide la table watchdog tous les jours' DO TRUNCATE TABLE watchdog
Le code est assez simple. Le « user » correspond à votre nom d’utilisateur, il faudra l’adapter en fonction de la configuration de votre serveur.
Vous devrez donner un nom explicite votre événement. De la même manière il faudra configurer la périodicité de l’événement. La dernière ligne contient la requête SQL à exécuter. Elle devra forcément commencer par « do ».
De nombreux outils permettent de générer automatiquement le code SQL. C’est notamment le cas de phpMyAdmin, qui est assez simple à utiliser. N’hésitez pas à l’utiliser.
Vous passez beaucoup de temps à chercher de l’information sur Internet, et donc vous vous retrouvez fréquemment face à des fichiers PDF. Et, malheureusement, au lieu de les ouvrir, Firefox les télécharge et vous laisse vous démerder avec. Ce qui est une perte de temps et énervant.
Voici la solution à vos problèmes, ou presque.
Paramètres
Pour gérer le comportement de Firefox il suffit d’aller dans le menu paramètres. Pour ce faire il existe trois méthodes, aussi simples les unes que les autres.
Dans le menu Outils, cliquez sur paramètres.
Cliquez sur le hamburger à droite de la fenêtre et, en bas du menu contextuel qui s’offre, cliquez sur paramètres.
Dans la barre d’adresse, tapez directement « about:preferences ».
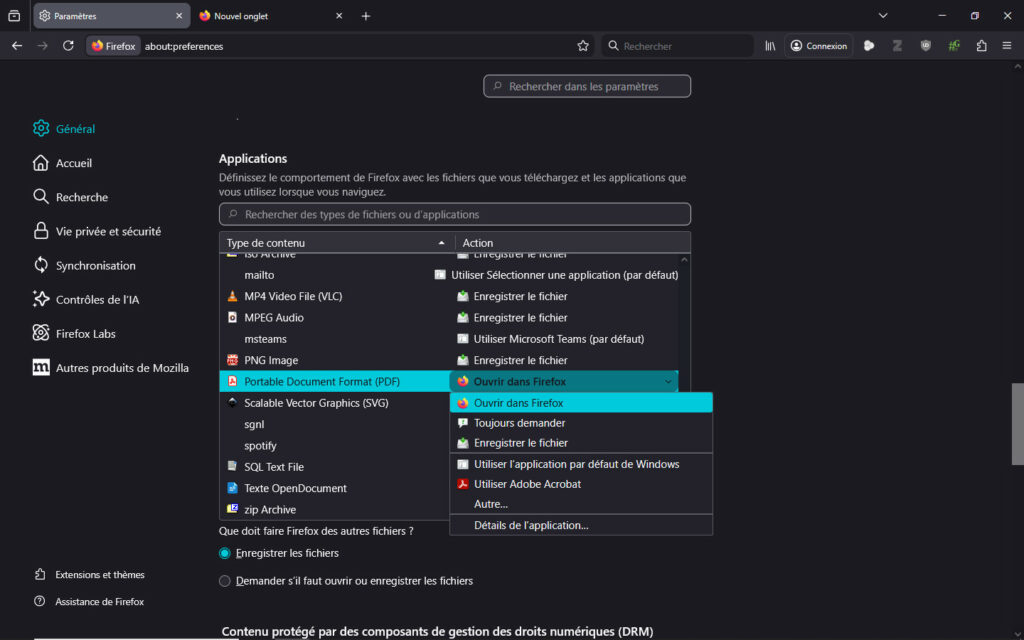
Dans le menu « Général » cherchez la section « Applications ». Dans le tableau il suffit de chercher la ligne correspondant au PDF, c’est-à-dire celle précisant « Format de document portable ». Il ne reste plus qu’à configurer le type d’action.
Configuration
Firefox vous propose 5 à 6 options.
Ouvrir dans Firefox, ou « Ouvrir dans Firefox (par défaut) » selon la version, ce qui permet d’ouvrir le fichier dans un nouvel onglet.
Toujours demander.
Enregistrer le fichier.
Utiliser l’application par défaut de Windows.
Utiliser Acrobat Reader (s’il est installé).
Autre (une liste des logiciels disponibles s’affichera).
Pour ouvrir de façon automatique il faut choisir la première option. Vous pourrez toujours changer d’avis en cours de route et modifier la configuration.
Une fois la configuration modifiée vous pouvez fermer cet onglet et retourner à votre navigation.